4月15日,中国科学院上海营养与健康研究所工程实验室人工智能与数字健康部团队在国际学术期刊Science Advances在线发表题为“Cross-species prediction reveals chromatin regions with increased accessibility in humans”的研究成果。该研究通过构建基于DNA序列的跨灵长类动物深度学习模型,系统揭示了人类特异性染色质开放性增强区域的演化规律与潜在功能。
人类独特的表型和对复杂疾病的易感性,大多源于基因组非编码区的调控差异。作为基因表达的核心调控元件,染色质开放区域的演化和功能研究对于解析人类特有性状的分子机制至关重要。然而,目前人类近缘灵长类物种的相关表观遗传数据十分稀缺,制约着人类演化调控机制的深入探索。
为此,研究团队巧妙地利用人工智能技术寻找破局之道。团队首先证实,仅利用人类数据训练的深度学习模型,就能精准预测灵长类动物的染色质开放程度,这表明深度学习可以有效捕捉“调控语法”的演化保守性。基于这一模型,团队最终在111种人类细胞类型中,鉴定出相对于祖先物种,人类特异的染色质开放性增强区域。这些区域具有高度的细胞特异性,不仅富集于基因表达调控核心元件,还受到正选择的作用;其内部的人类特有变异,更易改变转录因子结合位点,进而直接关联人类骨量变化、体脂增加等特有演化性状。
该研究突破了跨物种表观遗传学研究的数据壁垒,开辟了人类非编码序列演化研究的新路径,为解析人类特有表型形成的遗传基础提供了新策略。
中国科学院上海营养与健康研究所博士毕业生王临孝为该论文第一作者,王振研究员为通讯作者。该研究得到国家自然科学基金、国家重点研发计划等项目的资助。
论文链接:https://www.science.org/doi/10.1126/sciadv.ady9169
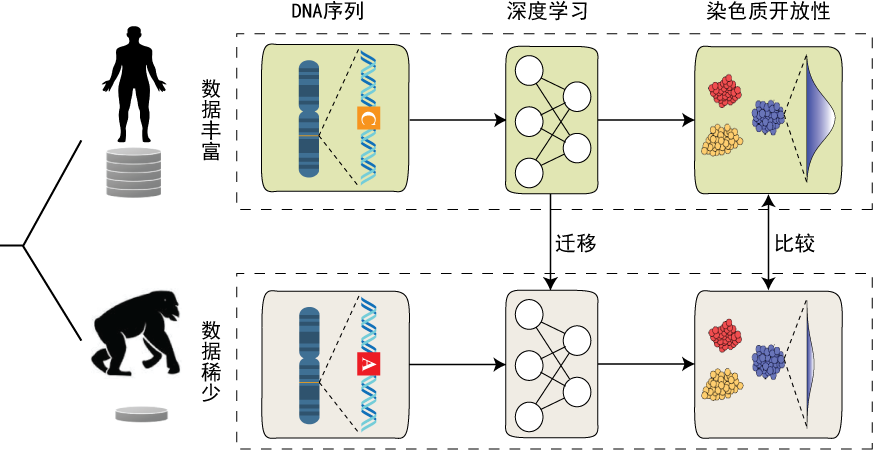
图:研究方法示意图。在非编码序列比较基因组学研究中,一大难题在于人类积累了丰富的表观基因组标记数据,而近缘灵长类物种则较为缺乏。为此,研究采用深度学习方法,将从人类数据中学习到的DNA序列与染色质开放性的对应关系迁移到近缘物种中,从而实现了物种间染色质开放性的比较。
推送单元:工程实验室人工智能与数字健康部、科技规划与任务处
 官方微信
官方微信